Spring Security의 SessionManagementConfigurer가 제공하는 sessionRegistry()는 일반적으로 인메모리 세션 관리를 사용합니다. 즉, 단일 JVM 인스턴스 내에서만 세션 정보를 추적하게 됩니다.
여러 인스턴스 또는 분산된 환경에서 애플리케이션을 실행하는 경우 (예: 클라우드 환경, 마이크로서비스 아키텍처, 로드 밸런서 뒤의 여러 서버 인스턴스) 이러한 인메모리 세션 관리 방식은 문제를 일으킬 수 있습니다. 왜냐하면 각 JVM 인스턴스는 자신만의 세션 정보를 가지고 있어서 다른 인스턴스의 세션 정보를 알지 못하기 때문입니다.
반면, SpringSessionBackedSessionRegistry는 Spring Session을 사용하며, Spring Session은 외부 저장소 (예: Redis, JDBC, Hazelcast 등)를 사용하여 세션 정보를 저장합니다. 이 방식을 사용하면 여러 애플리케이션 인스턴스 간에 세션 정보를 공유할 수 있습니다.
따라서:
단일 인스턴스 환경에서는 Spring Security의 기본 sessionRegistry()만으로도 충분합니다. 하지만 여러 인스턴스에서 세션 정보를 공유해야 하는 환경에서는 SpringSessionBackedSessionRegistry와 같은 방법을 사용하여 Spring Session을 활용해야 합니다. 이렇게 설정함으로써 여러 서버 인스턴스 간에 세션 정보를 일관되게 공유하면서 동시 로그인 제한과 같은 기능을 정상적으로 구현할 수 있습니다.
학원 운영을 하며 여러가지 관리할것들이 쌓이다보니, 상당히 복잡해져 웹서비스로 준비하게 되었다.
프론트엔드: DevExtreme 리액트 라이브러리
개인은 무료다. DataGrid, Shceduler, 기본 template으로 다 했다. jsp mvc에서는 화면을 전적으로 백엔드에서 통제를 하지만, 리액트에서는 별개로 돌아가기 때문에 강제로 로그인 이후 화면으로 진입한다면 리소스 제한만 했다. Doc를 보면서 화면을 제작하다보니 가장 많은 시간이 들어갔고, 컴포넌트 안에 컴포넌트를 반복해서 집어넣다보니 상태관리나 변수 조절이 까다로웠다.
백엔드: 스프링부트
JPA로 여러 엔티티를 모조리 관계를 맺었다. useYn 과 레코드 삭제(cascade)까지 사용했다. cascade 설정 시 customId를 사용하면 생성시기가 늦어 삭제가 안되므로 cascade적용 엔티티는 기본 id생성규칙을 따랐다. RDS로 설정했다가 비용이 많이나와서 ec2에 직접 mysql8을 설치해서 사용하는것으로 변경했다. 로컬 개발환경의 mysql과 ec2 의 것을 일치시키면 편하다. 스프링 시큐리티 로그인(jwt)을 적용했다.
2. aws으로
인스턴스 설정
처음 ami 고를 때 amazon linux 2023으로 했더니 mysql8설치가 귀찮아졌다. 빠르게 인스턴스 세팅을 다시 amazon linux 2로 하다가 인스턴스 유형을 x86 t2.micro에서 arm t4g.micro로 변경했다. 이유는 속도는 비슷하고 조금 더 싸다. 온디맨드 시간당 t2.micro : 0.0116USD, t4g.micro : 0.0084USD 프리티어는 날아가서 없다.
보안그룹
처음에 인스턴스 생성 시 보안그룹을 만들거나 기존것을 고른다. 인바운드: http로 들어오니 80포트 모두에게 쉘로 붙어야 하니 22포트 내 ip만 로컬에서 DB 넣어야 하니 3306포트 내 ip만, 아웃바운드는 다 허용
자바 설치
1
sudo yum list *java*
검색해서 원하는 것으로 설치한다. 나는 java-17-amazon-corretto-headless.aarch64 으로 설치했다.
1 2 3 4 5
java -version
openjdk version "17.0.7"2023-04-18 LTS OpenJDK Runtime Environment Corretto-17.0.7.7.1 (build 17.0.7+7-LTS) OpenJDK64-Bit Server VM Corretto-17.0.7.7.1 (build 17.0.7+7-LTS, mixed mode, sharing)
잘 나오니 환경변수 설정은 패스한다.
nginx 설치
인스턴스로 http를 타고 들어오면 80포트로 들어온다. 리액트를 빌드해서 스프링부트에 넣고 다시 war로 감싸서 8080포트로 들어가야 하므로 리버스 프록시 설정을 해줄 nginx를 설치한다.
1 2
sudo yum install nginx sudo vi /etc/nginx/nginx.conf
프로젝트에서 테스트하니 Public Key Retrieval is not allowed 발생.
방법1. url 에 allowPublicKeyRetrieval=true 붙이기
방법2. 사용자 인증 플러그인 native_password로 바꾸기
1
ALTERUSER'User'@'%' IDENTIFIED WITH mysql_native_password BY'비번';
나는 방법 2로 했다.
젠킨스 설치(패스)
젠킨스 설치는 다른데도 많으니 생략한다. 리액트를 eirslett 라이브러리를 써서 프로젝트 빌드시 리액트빌드-> resources/static으로 파일 이동 -> 스프링부트 빌드 -> target에 war 생성 순으로 설정했다. 그러나 리액트 빌드 도중 메모리 부족으로 실패.
# WAR 파일 경로 WAR_FILE="./dscheduler-0.0.1-SNAPSHOT.war"
# 포트 설정 PORT=8080
# Java 실행 명령어 JAVA_CMD="java"
# JVM 옵션 JAVA_OPTS="-Xmx512m -Xms256m"
# 로그 폴더 경로 LOG_FOLDER="./logs"
# 백그라운드에서 WAR 파일 실행 start() { echo"Starting the application..." LOG_FILE="$LOG_FOLDER/ssbScheduler-$(date +'%Y-%m-%d').log" nohup$JAVA_CMD$JAVA_OPTS -jar $WAR_FILE --server.port=$PORT > "$LOG_FILE" 2>&1 & echo"Application started. Logs are being saved to: $LOG_FILE" }
# 실행 중인 프로세스 종료 stop() { echo"Stopping the application..." PID=$(pgrep -f $WAR_FILE) if [ -n "$PID" ]; then kill$PID echo"Application stopped." else echo"Application is not running." fi }
# 명령어 파라미터에 따라 실행 case$1in start) start ;; stop) stop ;; *) echo"Usage: $0 {start|stop}" exit 1 ;; esac
탄력적 IP 설정 및 연결
ec2 > 탄력적IP -> 주소할당-> 주소연결(인스턴스로)
이렇게 인스턴스 세팅은 끝이다. 다음은 aws 세팅이다.
aws 설정
도메인(route53)
aws 콘솔>Route53>등록된 도메인>도메인 등록 도메인 골라서 결제(꽤비쌈) route53에서 도메인을 구매했더니 대기중인 요청에 한 10분정도 있다가 호스팅영역에 자동으로 추가되고 네임서버도 자동으로 등록이 되어있었다.
호스팅영역에서 ip를 연결한다. https인증서를 쓸려면 로드밸런서를 연결한다. 나는 1인 유저기때문에 바로 ip에 연결했다.
호스팅영역->레코드 생성. 아래와 같이 작성
레코드 이름: 원하는 이름 레코드 유형: A 값: 연결할 ip 입력. TTL: 300 라우팅 정책: 지리적위치(한국에서만) 위치: 한국 레코드ID: 내맘대로
RDS(적용취소)
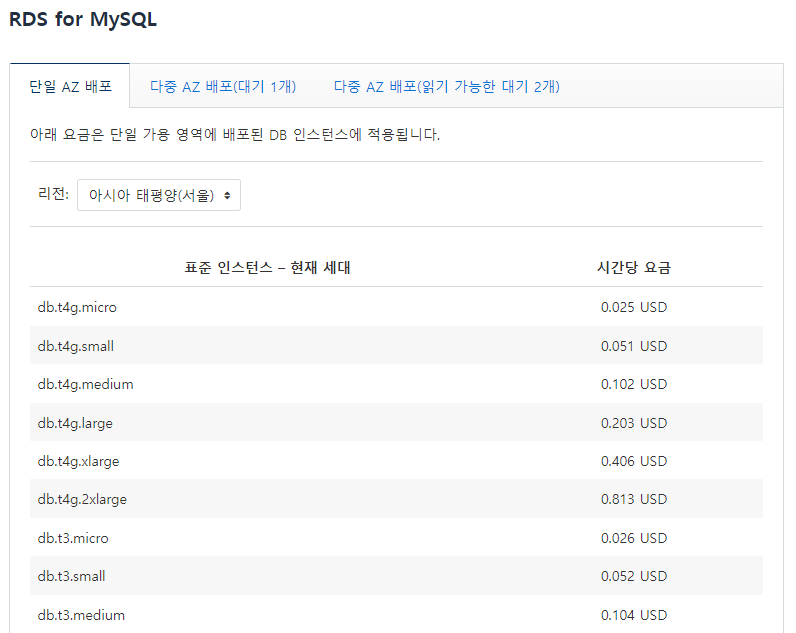
db.t3.small 싱글 인스턴스 가격 0.063USD/h 이 나와서 인스턴스 내 db를 설치해서 사용하기로 노선변경 가장 싼 db.t4g.micro 를 사용하면 0.025USD/h 한달에 3만원가량 -> 이건 무려 프리티어지만 나는 프리하지 않다.. 그 외 저장 비용등은 낮아서 생략한다.
SPOT인스턴스(적용취소)
RDS -> 로컬DB 사용으로 패스 RDS를 사용한다면 SPOT으로 변경하고 때때로 서비스 불량이 있을 수 있지만 가격이 낮아져 t4g.small을 사용할수도 있을 것 같다. 그러면 메모리가 2기가로 높아지고 속도가 올라가 리액트 빌드가 가능해지고 젠킨스를 사용할 수 있게 될것으로 예상 비용은 4만원/월 정도 예상
접속 순서 정리: 브라우저에서 설정한 도메인 입력 탄력ip로 연결 인스턴스 보안그룹 통과 nginx가 8080으로 연결 스프링부트에서 로컬 db 접근 스프링부트 내 index.html 으로 안내
스프링 부트 배치는 대량의 데이터를 처리하는데 유용한 프레임워크입니다. 이를 사용하면 일괄 처리(batch processing) 작업을 효율적으로 수행할 수 있습니다. 스프링 부트 배치는 다양한 구성 요소로 구성되며, 이러한 구성 요소는 특정 순서로 구동되어야 합니다. 이번 포스팅에서는 스프링 부트 배치 구동 순서에 대해 자세히 알아보겠습니다.
JobRepository 스프링 부트 배치는 먼저 JobRepository를 생성합니다. 이는 배치 작업을 수행하는 동안 상태 정보를 저장하는 데 사용됩니다. JobRepository는 데이터베이스를 기반으로 작동하며, 스프링 부트 배치는 사용자가 지정한 데이터베이스를 기본적으로 사용합니다.
JobLauncher JobRepository가 생성되면, 다음으로 JobLauncher가 생성됩니다. JobLauncher는 JobRepository를 사용하여 배치 작업을 시작합니다. 이를 위해 JobLauncher는 Job과 JobParameters를 매개변수로 받아들입니다.
Job JobLauncher가 생성되면 Job도 생성됩니다. Job은 일괄 처리 작업의 실행 단위입니다. Job은 하나 이상의 Step으로 구성됩니다.
Step Step은 일괄 처리 작업의 개별 단계를 정의합니다. Step은 Reader, Processor, Writer로 구성됩니다. Reader는 데이터 소스에서 데이터를 읽어들이고, Processor는 데이터를 가공하고, Writer는 가공된 데이터를 저장합니다.
ItemReader ItemReader는 Step에서 사용되며, 데이터 소스에서 데이터를 읽어들입니다.
ItemProcessor ItemProcessor는 Step에서 사용되며, 읽어들인 데이터를 가공합니다.
ItemWriter ItemWriter는 Step에서 사용되며, 가공된 데이터를 저장합니다.
ExecutionContext ExecutionContext는 Step의 상태 정보를 저장하는 데 사용됩니다. 이를 사용하여 다음 번 실행 시점에 이전 실행 결과를 기반으로 작업을 수행할 수 있습니다.
JobExecution JobExecution은 Job의 실행 상태 정보를 저장합니다. JobExecution은 JobRepository에 저장됩니다.
JobInstance JobInstance는 Job의 인스턴스를 나타냅니다. 즉, 동일한 Job을 여러 번 실행할 경우, 각 실행마다 별도의 JobInstance가 생성됩니다.
JobParameters JobParameters는 Job을 실행할 때 전달되는 매개변수입니다. 예를 들어, Job을 실행할 때 사용할 데이터베이스 연결 정보나 파일 경로 등을 전달할 수 있습니다.
이러한 구성 요소는 스프링 부트 배치를 구성하는 데 필요한 기본적인 요소입니다. 스프링 부트 배치를 사용할 때에는 이러한 구성 요소들이 어떻게 상호작용하는지 이해하는 것이 중요합니다. 일괄 처리 작업을 실행할 때, 스프링 부트 배치는 JobRepository를 사용하여 JobExecution과 StepExecution의 상태 정보를 저장하고, ExecutionContext를 사용하여 상태 정보를 공유합니다. 또한 JobLauncher를 사용하여 Job을 시작하고, Job은 하나 이상의 Step으로 구성되며, Step은 ItemReader, ItemProcessor, ItemWriter로 구성됩니다.
각 구성 요소들의 역할을 이해하면 스프링 부트 배치를 사용하여 일괄 처리 작업을 효율적으로 구현할 수 있습니다. 또한 스프링 부트 배치에서는 다양한 기능들을 제공하므로, 필요에 따라 설정을 변경하여 개인적인 요구사항에 맞게 사용할 수 있습니다. 예를 들어, Job의 실행 주기를 설정하거나, Step의 실행 순서를 변경하는 등의 설정을 변경할 수 있습니다.
스프링 부트 배치는 대규모 데이터 처리를 위한 강력한 프레임워크입니다. 이를 사용하여 데이터 처리 작업을 효율적으로 수행할 수 있으며, 이를 위해 필요한 구성 요소들을 제공합니다. 스프링 부트 배치의 구동 순서를 이해하고, 필요한 설정을 변경하여 개인적인 요구사항에 맞게 사용하면, 더욱 효율적으로 일괄 처리 작업을 수행할 수 있습니다.
스프링부트는 스프링 프레임워크를 기반으로 한 자바 웹 어플리케이션을 보다 쉽게 개발하고 운영하기 위해 만들어졌습니다. 다음과 같은 이유로 스프링부트를 쓰는 것이 유용합니다.
1. 빠른 개발
스프링부트는 설정이 간단하고, 빠른 애플리케이션 개발을 지원합니다. 개발자가 직접 설정을 할 필요 없이, 스프링부트의 자동설정을 이용하여 필요한 의존성을 추가하고 설정을 적용할 수 있습니다.
2. 간편한 배포
스프링부트는 내장된 서버(Tomcat, Jetty 등)를 이용하여 애플리케이션을 실행할 수 있습니다. 이는 개발자가 별도의 외부 서버를 구축하지 않아도 되며, 배포가 간단해집니다.
3. 통합된 모니터링
스프링부트는 애플리케이션의 상태를 모니터링할 수 있는 엔드포인트(Actuator)를 제공합니다. 이 엔드포인트를 이용하여 메모리 사용량, 쓰레드 개수, JDBC 연결 정보 등을 확인할 수 있습니다.
4. 간단한 테스트 환경 구축
스프링부트는 내장된 서버와 자동설정 기능을 이용하여 간단한 테스트 환경을 구축할 수 있습니다. 개발자는 별도의 서버나 DB 설정 없이 애플리케이션을 바로 테스트할 수 있습니다.
5. 다양한 환경 지원
스프링부트는 다양한 환경에서 애플리케이션을 실행할 수 있습니다. 클라우드 서비스(AWS, GCP 등)를 비롯하여, 스프링클라우드와 통합하여 클라우드에서 애플리케이션을 실행할 수 있습니다.
6. 자동설정 기능
스프링부트는 자동설정 기능을 제공하여 설정을 간단하게 처리할 수 있습니다. 예를 들어, JPA를 이용하여 DB 작업을 수행할 경우, 스프링부트는 자동으로 EntityManager를 생성하고, 트랜잭션 처리를 해줍니다.
7. 개발 환경 구축의 용이성
스프링부트는 개발환경을 구축하는데 있어 많은 도움을 줍니다. Maven, Gradle 등의 빌드 툴을 이용하여 의존성을 관리하고, JAR, WAR 파일을 쉽게 빌드할 수 있습니다. 또한 스프링부트는 스프링 이니셜라이저를 제공하여, 초기 설정을 쉽게 생성할 수 있습니다.
8. 관련 커뮤니티
스프링부트는 스프링 프레임워크를 기반으로 하기 때문에, 스프링 프레임워크와 관련된 다양한 커뮤니티를 활용할 수 있습니다. 또한 스프링부트는 다양한 라이브러리와 프레임워크와 연동이 가능합니다.
9. 성능
스프링부트는 내장된 서버를 이용하므로, 서버를 구축하지 않아도 되며, 클라우드에서 애플리케이션을 실행할 수 있어, 성능면에서 우수한 결과를 보입니다. 또한, 스프링부트는 내부적으로 캐싱을 적용하여 성능을 향상시킬 수 있습니다.
10. 다양한 기능
스프링부트는 다양한 기능을 제공합니다. AOP, 캐싱, 보안 등 다양한 모듈을 이용하여 애플리케이션을 구성할 수 있습니다. 또한, 스프링부트는 스프링데이터를 이용하여 다양한 데이터베이스를 지원하며, 스프링 시큐리티를 이용하여 보안기능을 구현할 수 있습니다.
스프링부트는 스프링 프레임워크를 보다 쉽게 사용할 수 있도록 만들어졌습니다. 스프링부트를 이용하면 애플리케이션을 빠르게 개발하고, 배포할 수 있으며, 모니터링과 테스트를 간편하게 수행할 수 있습니다. 또한, 다양한 커뮤니티와 라이브러리를 활용하여 애플리케이션을 보다 높은 수준으로 구현할 수 있습니다. 따라서, 스프링부트는 자바 개발자에게 권장되는 프레임워크 중 하나입니다.
스프링부트는 왜 생겨났을까?
스프링부트는 스프링 프레임워크를 기반으로 한 자바 웹 어플리케이션을 보다 쉽게 개발하고 운영하기 위해 만들어졌습니다. 이전에는 스프링 프레임워크를 이용한 개발 시 많은 설정과 라이브러리가 필요했고, 이를 일일이 구성하는 것이 어려웠습니다. 이러한 문제를 해결하기 위해 스프링부트는 자동설정과 스타터(dependency management)를 제공하여 개발자가 불필요한 설정 및 의존성 관리에 신경쓰지 않고, 개발에 집중할 수 있도록 도와줍니다.
스프링부트의 개발 목적은 다음과 같습니다.
개발자 생산성 향상
스프링부트는 자동설정, 스타터, CLI(Command Line Interface) 등을 제공하여 개발자가 빠르게 개발할 수 있도록 돕습니다.
설정 간소화
스프링부트는 설정 파일의 크기를 줄이고, 불필요한 설정을 자동으로 제거하여 개발자가 설정 관리를 쉽게 할 수 있도록 돕습니다.
내장 서버 제공
스프링부트는 내장된 서버를 제공하여 개발자가 별도의 서버를 구축하지 않아도 애플리케이션을 실행할 수 있습니다.
확장 가능성
스프링부트는 스프링 프레임워크와 연동하여 스프링의 다양한 모듈과 기능을 활용할 수 있습니다.
운영 및 배포의 용이성
스프링부트는 애플리케이션의 설정과 라이브러리 의존성을 자동으로 관리하여, 배포 시 일관된 환경을 제공합니다. 또한, 애플리케이션의 상태를 모니터링할 수 있는 엔드포인트를 제공하여, 운영 및 모니터링을 용이하게 합니다.
스프링 DI (Dependency Injection)
DI는 Dependency Injection의 약자로, 객체간의 의존성을 느슨하게 만들기 위한 디자인 패턴 중 하나입니다. 객체가 직접 의존하는 객체를 생성하거나, 컨테이너가 직접 생성하여 의존성을 주입하는 방식으로 작동합니다.
스프링에서는 DI를 위해 @Autowired 어노테이션을 제공합니다. @Autowired 어노테이션을 사용하여 의존성 주입을 자동화할 수 있습니다. 이를 통해 객체 간의 결합도를 낮추고, 유지보수 및 확장성을 높일 수 있습니다.
객체 주입 방식의 종류와 특징
DI (Dependency Injection)는 객체 간의 의존성을 낮추기 위한 디자인 패턴으로, 스프링에서는 다양한 객체 주입 방식을 제공합니다. 여러 객체 주입 방식의 특징과 차이점을 살펴보겠습니다.
1. 생성자 주입(Constructor Injection)
생성자 주입은 객체를 생성할 때, 생성자를 통해 의존성을 주입하는 방식입니다. 생성자 주입 방식은 다음과 같은 특징이 있습니다.
불변성(Immutability): 생성자를 통해 한 번 주입되면 의존성을 변경할 수 없습니다.
필수적인 의존성 주입: 모든 의존성이 생성자에 주입되어야 하기 때문에, 필수적인 의존성이 존재할 경우 사용합니다.
Setter 주입과 메서드 주입(Method Injection)은 서로 비슷한 방법으로 의존성을 주입하는 방식이지만, 몇 가지 차이점이 있습니다.
Setter 주입은 객체 생성 후, Setter 메서드를 통해 의존성을 주입하는 방식입니다. 이 방식은 의존성이 변경될 가능성이 있는 경우, Setter 메서드를 통해 의존성을 변경할 수 있는 장점이 있습니다.
메서드 주입은 생성자나 Setter 메서드가 아닌, 클래스 내부의 일반적인 메서드를 통해 의존성을 주입하는 방식입니다. 이 방식은 객체 생성 시점에 의존성이 결정되지 않아도 되는 장점이 있으며, Setter 메서드와 달리 메서드 이름에 제약이 없는 유연한 방식입니다.
즉, Setter 주입과 메서드 주입은 서로 다른 방식의 의존성 주입 방법입니다. Setter 주입은 Setter 메서드를 이용하여 의존성을 주입하고, 메서드 주입은 생성자나 Setter 메서드 이외의 일반적인 메서드를 이용하여 의존성을 주입합니다.
객체 주입 방식 선택 시 고려해야 할 사항
객체 주입 방식을 선택할 때 고려해야 할 사항은 다음과 같습니다.
의존성의 필수/선택 여부: 생성자 주입 방식은 모든 의존성을 필수적으로 주입해야 하기 때문에, 필수적인 의존성이 존재하는 경우에 사용됩니다. 반면에 Setter 주입 방식은 선택적인 의존성이 존재하는 경우에 사용됩니다.
객체의 불변성: 생성자 주입 방식은 의존성이 주입된 이후에는 의존성을 변경할 수 없습니다. 따라서 불변성이 필요한 객체에는 생성자 주입 방식이 적합합니다.
유연성: Setter 주입 방식은 Setter 메서드를 통해 의존성을 변경할 수 있기 때문에, 의존성 변경이 빈번하게 발생하는 경우에 적합합니다.
코드 가독성: 필드 주입 방식은 필드를 직접 주입하기 때문에, 코드 가독성이 저하될 수 있습니다. 따라서 코드 가독성이 중요한 경우에는 생성자 주입 방식이나 Setter 주입 방식을 사용하는 것이 좋습니다.
특정 메서드를 통한 의존성 주입: 메서드 주입 방식은 특정 메서드를 통해 의존성을 주입하기 때문에, 특정 메서드에 대해 유연하게 처리할 수 있습니다.
스프링 IOC (Inversion of Control)
스프링의 핵심 컨테이너인 ApplicationContext는 Inversion of Control(IoC)을 구현한 것입니다. IoC는 객체 지향 프로그래밍에서 발생하는 의존성 관리 문제를 해결하기 위해 등장한 개념으로, 객체 간의 의존성을 자동으로 연결해주는 프로그래밍 방식입니다.
스프링의 IoC는 객체의 생성, 소멸 등의 라이프사이클을 관리하며, 객체 간의 의존성을 관리하는 데에 중점을 둡니다. IoC는 객체 간의 의존성을 자동으로 연결해주는 역할을 합니다.
스프링의 IoC는 객체를 생성하는 시점과 의존성을 주입하는 시점을 분리합니다. 이를 통해 객체의 라이프사이클을 유연하게 관리할 수 있습니다. 스프링의 IoC는 객체 간의 의존성을 자동으로 주입해주는데, 이를 의존성 주입(Dependency Injection, DI)이라고 합니다.
스프링의 IoC는 빈(Bean)이라는 단위로 객체를 관리합니다. 빈은 ApplicationContext에 등록되어 있으며, 다른 빈에서 의존성 주입을 받을 수 있습니다. 빈은 XML 설정 파일이나 어노테이션을 이용하여 등록할 수 있습니다.
스프링의 IoC는 다양한 방식으로 의존성 주입을 처리합니다. 주요한 의존성 주입 방식으로는 생성자 주입(Constructor Injection), Setter 주입(Setter Injection), 필드 주입(Field Injection) 등이 있습니다. 이들은 각각 객체 생성 시점에 의존성을 주입하는 방식이 다르며, 상황에 따라 선택해서 사용할 수 있습니다.
스프링의 IoC는 객체의 생성과 소멸, 의존성 주입 등을 자동으로 처리해주므로, 객체 간의 의존성 관리 문제를 해결할 수 있습니다. 이를 통해 코드의 재사용성과 유지보수성을 높일 수 있습니다.
스프링 AOP
AOP(Aspect-Oriented Programming)는 객체 지향 프로그래밍의 한계를 보완하기 위해 등장한 프로그래밍 패러다임입니다. AOP는 애플리케이션의 핵심 로직에서 발생하는 부가적인 작업들을 모듈화하여 코드의 재사용성과 유지보수성을 높여줍니다.
스프링 AOP는 스프링 프레임워크에서 제공하는 AOP 구현체입니다. 스프링 AOP는 프록시 패턴을 이용하여 메서드 실행 전/후 등 특정 시점에 부가적인 로직을 수행할 수 있습니다.
스프링 AOP의 주요 구성 요소는 다음과 같습니다.
Pointcut
Advice가 적용될 메서드를 지정하는 것을 의미합니다.
Advice
메서드 실행 전/후 등 특정 시점에서 수행할 로직을 정의합니다.
Joinpoint
Advice가 적용될 수 있는 위치를 의미합니다. 메서드 호출, 예외 발생 등이 Joinpoint에 해당합니다.
Aspect
Pointcut과 Advice의 결합체를 의미합니다.
Target
AOP가 적용되는 대상 객체를 의미합니다.
스프링 AOP는 다양한 Advice를 지원합니다.
Before
메서드 실행 전에 수행할 로직을 정의합니다.
After returning
메서드 실행 후 리턴 값이 존재할 경우 수행할 로직을 정의합니다.
After throwing
메서드 실행 중 예외가 발생한 경우 수행할 로직을 정의합니다.
After
메서드 실행 후 수행할 로직을 정의합니다.
Around
메서드 실행 전/후 등 모든 시점에서 수행할 로직을 정의합니다.
스프링 AOP는 자바의 Proxy 클래스를 이용하여 프록시 객체를 생성합니다. 이를 통해 타깃 객체의 메서드를 호출하기 전/후에 부가적인 로직을 수행할 수 있습니다. 또한, AOP를 적용할 때 XML 설정 파일이나 어노테이션을 이용하여 간편하게 설정할 수 있습니다.
스프링 AOP를 사용하면 애플리케이션의 핵심 로직과 부가적인 로직을 분리하여 구현할 수 있습니다. 이를 통해 코드의 재사용성과 유지보수성을 높일 수 있으며, 특히 로깅, 트랜잭션, 보안 등과 같은 공통적인 작업을 간편하게 처리할 수 있습니다.
스프링 ORM (Object-Relational Mapping)
ORM은 Object-Relational Mapping의 약자로, 객체와 관계형 데이터베이스 간의 매핑을 자동화하는 기술입니다. 스프링에서는 JPA(Java Persistence API)를 이용하여 ORM을 구현합니다.
스프링에서 ORM을 이용하면 객체지향적인 방식으로 데이터를 다룰 수 있습니다. 또한, ORM을 이용하면 SQL을 직접 작성하는 것보다 더 간편하게 데이터를 다룰 수 있습니다. 스프링에서는 Hibernate, MyBatis 등 다양한 ORM 프레임워크를 지원합니다.
Hibernate
Hibernate는 자바 언어를 위한 ORM(Object-Relational Mapping) 프레임워크입니다. ORM은 객체와 관계형 데이터베이스 간의 매핑을 자동으로 처리하는 기술입니다. 이를 통해 SQL 쿼리를 직접 작성하지 않아도 데이터베이스와 상호작용할 수 있습니다.
Hibernate는 객체와 데이터베이스 간의 매핑을 위해 XML 또는 어노테이션을 사용할 수 있습니다. Hibernate는 객체를 데이터베이스 테이블에 매핑하는 방식으로 동작합니다. 이를 위해 개발자는 데이터베이스 스키마와 매핑되는 Java 클래스를 작성하고, Hibernate 설정 파일을 작성하여 데이터베이스 연결 정보를 설정합니다.
Hibernate는 자바 Persistence API(JPA)를 구현하는 ORM 프레임워크입니다. JPA는 Java에서 ORM을 구현하기 위한 표준 인터페이스입니다. Hibernate는 JPA의 구현체 중 하나로, JPA에서 정의한 인터페이스를 구현하여 ORM을 제공합니다.
Hibernate는 데이터베이스와의 상호작용을 위해 Session과 Transaction 개념을 사용합니다. Session은 데이터베이스와의 세션을 의미하며, 데이터베이스 연결과 동일한 개념입니다. Transaction은 데이터베이스에서 수행되는 일련의 작업을 의미하며, 일반적으로 Session 내에서 실행됩니다.
Hibernate의 주요 기능으로는 다음과 같은 것들이 있습니다.
객체와 데이터베이스 간의 매핑 처리 객체와 데이터베이스 간의 관계 처리 객체와 데이터베이스 간의 쿼리 처리 객체와 데이터베이스 간의 트랜잭션 처리 Hibernate는 자바에서 ORM을 구현하는 대표적인 프레임워크 중 하나입니다. JPA를 구현한 ORM 프레임워크 중에서도 가장 널리 사용되는 프레임워크 중 하나이며, 대규모 애플리케이션에서도 안정적으로 사용됩니다.
MyBatis 와 Hibernate
MyBatis와 Hibernate은 모두 자바에서 사용되는 ORM 프레임워크입니다. 하지만, MyBatis는 Hibernate과는 다른 방식으로 동작합니다.
MyBatis는 SQL 매핑 기반의 ORM 프레임워크로, 개발자가 직접 SQL 쿼리를 작성하고, 데이터베이스와 상호작용할 수 있는 방식으로 동작합니다. MyBatis는 SQL 매핑 파일과 Java 인터페이스를 이용하여 데이터베이스와의 상호작용을 처리합니다. 이에 비해 Hibernate는 객체와 데이터베이스 간의 매핑을 처리하며, SQL 쿼리를 자동으로 생성합니다.
MyBatis는 JDBC를 이용하여 데이터베이스와 상호작용하며, SQL 쿼리를 직접 작성할 수 있습니다. 반면, Hibernate는 JDBC보다 더 높은 추상화 수준을 제공하며, 객체와 데이터베이스 간의 매핑을 자동으로 처리합니다.
따라서, MyBatis는 Hibernate과는 다른 방식으로 동작합니다. MyBatis에서는 Hibernate과 같은 ORM 프레임워크에서 제공하는 객체와 데이터베이스 간의 매핑 기능이 제한적이며, 대신 SQL 쿼리를 직접 작성하여 데이터베이스와 상호작용하는 방식으로 동작합니다.
스프링 MVC life cycle
스프링 MVC의 라이프사이클은 크게 다음과 같은 단계로 구성됩니다.
요청 처리 과정 시작
HandlerMapping을 통한 핸들러 검색
HandlerAdapter를 통한 핸들러 실행
ViewResolver를 통한 뷰 검색
ModelAndView를 이용한 뷰 실행
요청 처리 과정 종료
요청 처리 과정 시작 사용자가 HTTP 요청을 서버에 전송하면, 해당 요청은 DispatcherServlet에 의해 처리됩니다. DispatcherServlet은 스프링 컨테이너에 등록된 모든 빈을 검색하며, HandlerMapping, HandlerAdapter, ViewResolver 등의 빈을 찾아 사용합니다.
HandlerMapping을 통한 핸들러 검색 DispatcherServlet은 HandlerMapping 빈을 찾아 핸들러를 검색합니다. HandlerMapping은 요청 URI를 이용하여 적절한 핸들러를 검색하며, 해당 핸들러가 없을 경우 404 에러를 반환합니다.
HandlerAdapter를 통한 핸들러 실행 HandlerMapping을 통해 검색된 핸들러는 HandlerAdapter를 이용하여 실행됩니다. HandlerAdapter는 검색된 핸들러가 처리할 수 있는 형태로 요청을 변환하고, 핸들러가 처리한 결과를 ModelAndView 객체에 담아 반환합니다.
ViewResolver를 통한 뷰 검색 ModelAndView 객체는 DispatcherServlet에 반환됩니다. DispatcherServlet은 ViewResolver 빈을 이용하여 뷰를 검색합니다. ViewResolver는 검색된 뷰의 위치와 형식을 찾아 반환합니다.
ModelAndView를 이용한 뷰 실행 검색된 뷰는 DispatcherServlet에 의해 실행됩니다. ModelAndView 객체에 담겨있는 데이터를 이용하여 뷰가 생성되며, HTML, JSP, JSON 등의 형식으로 응답됩니다.
요청 처리 과정 종료 뷰가 실행된 후, DispatcherServlet은 요청 처리 과정을 종료합니다. 이때, 요청과 응답 객체는 Servlet Container에 반환됩니다.
스프링 MVC의 라이프사이클은 요청 처리에 필요한 여러 개의 빈들을 순서에 맞게 실행하며, 요청과 응답 객체를 생성 및 관리합니다. 이를 통해 사용자 요청에 대한 적절한 응답을 반환할 수 있습니다.
스프링 배치는 대량의 데이터를 처리하는 데 유용한 오픈소스 프레임워크이다. 이를 이용하여 데이터베이스나 파일 시스템과 같은 데이터 저장소에서 데이터를 추출하고 가공한 후, 다시 저장소에 저장하는 등의 작업을 수행할 수 있다. 이를 통해 대량의 데이터를 효율적으로 처리할 수 있으며, 이를 자동화하여 일괄처리를 가능하게 하여 개발자의 업무 효율성을 높일 수 있다.
스프링 배치의 장점은 다음과 같다.
대량의 데이터를 처리하는데 최적화되어 있다.
배치 작업의 이력을 관리하며, 실패한 작업을 다시 수행할 수 있다.
스케줄링 기능을 지원하여 주기적인 작업을 자동화할 수 있다.
재사용성이 높은 컴포넌트 기반 아키텍처를 제공한다.
따라서, 대량의 데이터를 처리하고자 할 때 스프링 배치를 사용하는 것이 유용하며, 스프링 프레임워크를 사용하는 경우에는 쉽게 연동하여 사용할 수 있다.
사용 선택 기준
스프링 배치를 사용하는 것이 적절한 경우는 대량의 데이터를 처리해야 할 때입니다. 이를 자동화하여 일괄 처리하고자 하는 경우에도 스프링 배치는 유용합니다. 예를 들어, 은행에서는 매일 수백만 건의 거래 데이터를 처리해야 하므로, 이를 스프링 배치를 이용하여 처리할 수 있습니다.
장점
대량의 데이터를 처리하는 데 최적화되어 있습니다.
배치 작업의 이력을 관리할 수 있어, 실패한 작업을 다시 수행할 수 있습니다.
스케줄링 기능을 제공하여 주기적인 작업을 자동화할 수 있습니다.
재사용성이 높은 컴포넌트 기반 아키텍처를 제공합니다.
단점
배치 작업을 위한 코드를 작성하려면 일정한 학습 곡선이 필요합니다.
배치 작업을 디버깅하고 문제를 해결하는 데 시간이 걸릴 수 있습니다.
멱등성은 어떻게 유지하는가?
멱등성이란, 같은 작업을 여러 번 수행해도 결과가 변하지 않는 성질을 말합니다. 스프링 배치에서는 이러한 멱등성을 유지하기 위해 여러 가지 방법을 제공합니다. 예를 들어, 아래와 같은 방법으로 멱등성을 유지할 수 있습니다.
BatchStatus 컬럼을 이용하여 이미 성공한 작업은 다시 수행하지 않도록 합니다.
JobInstance와 JobExecution의 ID를 이용하여 이미 실행한 작업을 식별하고 중복 실행을 방지합니다.
스프링 배치 메타데이터 테이블은 어떤 것이 있나?
스프링 배치에서는 배치 작업의 메타데이터를 저장하기 위한 테이블을 제공합니다. 이 테이블은 JobRepository 인터페이스를 통해 접근할 수 있습니다. 스프링 배치가 제공하는 기본 메타데이터 테이블은 다음과 같습니다.
BATCH_JOB_INSTANCE: JobInstance 정보를 저장합니다.
BATCH_JOB_EXECUTION: JobExecution 정보를 저장합니다.
BATCH_JOB_EXECUTION_CONTEXT: JobExecution의 ExecutionContext 정보를 저장합니다.
BATCH_STEP_EXECUTION: StepExecution 정보를 저장합니다.
BATCH_JOB_PARAMS: Job 파라미터 정보를 저장합니다.
BATCH_STEP_EXECUTION_CONTEXT: StepExecution의 ExecutionContext 정보를 저장합니다.
배치 실행 도중 실패시 처리 방법?
스프링 배치에서 배치 실행 도중 실패한 경우, 실패한 스텝을 재시도하거나 다음 스텝으로 진행하지 않고 중단하는 등의 처리 방법을 선택할 수 있습니다. 이러한 처리 방법을 설정하기 위해서는 Retry와 Skip 기능을 이용할 수 있습니다.
Retry: 스텝이 실패한 경우 지정된 횟수만큼 재시도합니다. 예를 들어, ItemReader에서 데이터를 읽어올 때 DB 커넥션 오류 등으로 인해 실패한 경우, 일정 시간이 지난 후에 다시 시도합니다.
Skip: 스텝이 실패한 경우, 실패한 데이터를 스킵하고 다음 데이터로 넘어갑니다. 이를 이용하여, 예외가 발생해도 작업이 중단되지 않도록 할 수 있습니다.
스프링 배치 멀티스레드, 파티션 방법과 차이점
스프링 배치에서 멀티스레드와 파티션 방법은 모두 대량의 데이터를 처리하는 데 사용됩니다. 멀티스레드는 스텝 내에서 다수의 스레드를 사용하여 처리 속도를 높이는 방법이고, 파티션 방법은 여러 개의 작은 작업 단위로 분할하여 병렬 처리하는 방법입니다. 두 방법의 차이점은 다음과 같습니다.
멀티스레드: 스텝 내에서 스레드를 사용하여 처리합니다. 하나의 스텝을 여러 개의 스레드로 분할하여 처리할 수 있습니다. 처리 속도를 높일 수 있으나, 스레드 간의 동기화 문제나 데드락 등의 문제가 발생할 수 있습니다.
파티션: 대량의 데이터를 작은 단위로 나누어 여러 개의 스텝으로 분할하여 처리합니다. 각각의 스텝은 병렬로 처리됩니다. 데이터 분할이 복잡하고 처리 과정에서 추가적인 오버헤드가 발생할 수 있습니다.
스프링배치에서 트랜잭션 관리를 왜 청크 단위로 하는지
스프링 배치에서 트랜잭션 관리는 청크 단위로 수행됩니다. 이는 대량의 데이터를 처리할 때 메모리 부족 현상을 방지하고, 롤백 시에도 데이터 일관성을 유지하기 위한 것입니다. 예를 들어, 10000건의 데이터를 처리하는데 트랜잭션 범위를 1건 단위로 처리하면, 10000번의 INSERT 작업마다 커밋을 수행해야 합니다. 이는 DB나 메모리 등에서 성능 저하를 일으킬 수 있으며, 롤백 시에도 일부 데이터만 롤백되어 데이터 일관성이 깨질 가능성이 있습니다. 하지만 청크 단위로 처리하면, 1000건 단위로 처리하면 10번의 INSERT 작업마다 커밋을 수행하므로 성능 저하 문제가 줄어들고, 롤백 시에도 청크 단위로 롤백되어 데이터 일관성이 유지됩니다.
테스킷 vs Reader/Writer 차이
테스킷(Tasklet)과 Reader/Writer는 스프링 배치에서 데이터 처리를 위해 사용되는 두 가지 방법입니다. 테스킷은 간단한 처리를 수행하고 스텝을 종료할 때 사용되는 반면, Reader/Writer는 대량의 데이터 처리를 위해 사용됩니다.
테스킷: 스텝 내에서 수행되는 단일 작업입니다. 스텝 시작 시 한 번만 실행되며, 간단한 데이터 처리를 수행합니다. 예를 들어, 파일을 이동하거나, 이메일을 발송하는 등의 작업을 수행할 수 있습니다.
Reader/Writer: 대량의 데이터 처리를 위해 사용됩니다. Reader는 데이터를 읽어오고, Writer는 데이터를 저장합니다. 예를 들어, 데이터베이스에서 대량의 데이터를 읽어와서 파일로 저장하는 등의 작업을 수행할 수 있습니다.
배치 실행은? 젠킨스(실행 및 스케쥴링) 관점으로
젠킨스에서 스프링 배치를 실행하고 스케줄링하는 방법은 다음과 같습니다.
젠킨스 홈페이지에 접속합니다.
젠킨스 대시보드에서 “새로운 Item 생성” 버튼을 클릭합니다.
“스프링 배치 프로젝트”를 선택합니다.
필요한 설정을 입력합니다. (프로젝트 이름, 저장소, 빌드 설정 등)
“빌드 유발” 탭에서 “정기적으로 빌드”를 선택하고, 스케줄링을 설정합니다.
“빌드” 탭에서 스프링 배치를 실행하는 명령어를 입력합니다. (예: java -jar batch.jar)
배치 보니터링 방법은? 지연되는 배치 등 모니터링 및 후속 처리 관점으로
스프링 배치의 모니터링 및 후속 처리는 스프링 배치가 제공하는 JobExplorer를 이용하여 수행할 수 있습니다. JobExplorer는 배치 작업의 상태를 조회하고, 재시작 및 중지 등의 제어를 수행할 수 있습니다. JobExplorer를 이용하여 지연되는 배치 작업 등을 모니터링하고, 후속 처리를 수행할 수 있습니다. 예를 들어, 아래와 같은 방법으로 JobExplorer를 이용하여 배치 작업을 모니터링할 수 있습니다.
JobExplorer를 이용하여 JobInstance와 JobExecution 정보를 조회합니다.
조회한 정보를 이용하여 JobExecution의 상태를 확인하고, 작업이 지연되었는지 확인합니다.
이진 탐색 트리(Binary Search Tree)는 이진 트리(Binary Tree)의 한 종류로서, 각 노드가 하나의 키(Key)를 저장하는 자료 구조입니다. 이진 탐색 트리는 다음과 같은 특성을 가지고 있습니다.
루트 노드를 기준으로 왼쪽 서브트리의 키는 모두 루트 노드의 키보다 작습니다.
루트 노드를 기준으로 오른쪽 서브트리의 키는 모두 루트 노드의 키보다 큽니다.
왼쪽 서브트리와 오른쪽 서브트리도 모두 이진 탐색 트리여야 합니다.
중복된 키를 가지지 않습니다.
이진 탐색 트리에서는 탐색, 삽입, 삭제 연산을 O(log n)의 시간 복잡도로 수행할 수 있습니다. 이진 탐색 트리는 탐색이나 삽입, 삭제 연산을 할 때, 항상 트리의 루트 노드부터 시작하여 탐색하므로 탐색 범위를 빠르게 줄일 수 있습니다.
이진 탐색 트리는 정렬된 데이터의 삽입/삭제/검색에 적합한 자료 구조입니다. 하지만 트리의 구조가 한쪽으로 치우칠 경우, 트리의 높이가 길어져 연산 속도가 떨어지는 문제가 있습니다. 이러한 문제를 해결하기 위해 AVL 트리, 레드-블랙 트리 등의 균형 이진 탐색 트리가 개발되었습니다.
내부적으로 해시 테이블을 사용하여 데이터를 저장합니다. 데이터의 중복을 허용하지 않습니다. 데이터의 순서가 보장되지 않습니다. 삽입, 삭제, 검색 시 O(1)의 시간 복잡도를 갖습니다. 순서가 중요하지 않은 데이터의 집합에 적합합니다.
TreeSet
내부적으로 이진 검색 트리를 사용하여 데이터를 저장합니다. 데이터의 중복을 허용하지 않습니다. 데이터의 순서가 정렬된 상태로 저장되며, 이진 검색 트리를 사용하기 때문에 검색 속도가 빠릅니다. 삽입, 삭제, 검색 시 O(log n)의 시간 복잡도를 갖습니다. 순서가 중요하거나, 정렬된 데이터의 집합에 적합합니다. 따라서, HashSet은 데이터의 순서가 중요하지 않을 때 사용하고, TreeSet은 데이터의 순서가 중요하거나 정렬된 데이터의 집합에서 사용하는 것이 적합합니다. TreeSet은 검색 속도가 빠르지만, 데이터의 크기가 커질수록 검색 속도가 느려질 수 있습니다. HashSet은 검색 속도가 일정하며, 데이터의 크기가 커져도 검색 속도에 큰 변화가 없습니다.
List는 순서가 있는 데이터의 집합입니다. 데이터의 중복을 허용합니다. 대표적인 구현 클래스로는 ArrayList, LinkedList, Vector가 있습니다.
ArrayList: 내부적으로 배열을 사용하여 데이터를 저장합니다. 데이터 추가/삭제 시 기존 데이터를 복사하거나 이동해야 하는 단점이 있습니다. 대용량 데이터의 경우 불리할 수 있습니다. LinkedList: 데이터를 연결 리스트로 구현하여 저장합니다. 데이터 추가/삭제 시 다른 데이터를 영향받지 않으며, 데이터의 위치를 이동시키는 것이 간단합니다. Vector: ArrayList와 유사하지만, 멀티스레드 환경에서 동기화된 메서드를 제공합니다. 대부분의 경우 ArrayList를 대신하여 사용됩니다.
Set
Set은 순서가 없는 데이터의 집합입니다. 데이터의 중복을 허용하지 않습니다. 대표적인 구현 클래스로는 HashSet, TreeSet이 있습니다.
HashSet: 내부적으로 HashMap을 사용하여 데이터를 저장합니다. 데이터의 중복을 허용하지 않으며, 순서가 없습니다. 검색 속도가 빠릅니다. TreeSet: 데이터를 정렬하여 저장합니다. 데이터의 중복을 허용하지 않으며, 오름차순이나 내림차순으로 데이터를 정렬할 수 있습니다.
Map
Map은 key-value 쌍으로 이루어진 데이터의 집합입니다. key는 중복될 수 없으며, value는 중복될 수 있습니다. 대표적인 구현 클래스로는 HashMap, TreeMap이 있습니다.
HashMap: 내부적으로 해시 테이블을 사용하여 key-value 쌍을 저장합니다. key의 중복을 허용하지 않으며, 순서가 없습니다. 검색 속도가 빠릅니다. TreeMap: 데이터를 정렬하여 key-value 쌍을 저장합니다. key의 중복을 허용하지 않으며, 오름차순이나 내림차순으로 데이터를 정렬할 수 있습니다.
종류 별 선택방법
1. 데이터의 종류와 크기에 따라 선택하기
데이터의 종류와 크기에 따라 적절한 컬렉션 클래스를 선택하는 것이 중요합니다. 예를 들어, 원소의 개수가 많은 경우에는 검색 속도가 빠른 HashSet이나 HashMap을 사용하는 것이 좋습니다.
2. 데이터의 추가/삭제 빈도에 따라 선택하기
데이터의 추가/삭제 빈도에 따라 LinkedList나 TreeSet을 선택할 수 있습니다. 데이터의 추가/삭제가 빈번하게 일어나는 경우, LinkedList는 다른 데이터를 영향받지 않아 데이터 처리 속도가 빠릅니다. TreeSet은 데이터의 추가/삭제가 적은 경우에 사용할 수 있으며, 데이터를 정렬하여 저장하기 때문에 검색 속도가 빠릅니다.
3. 데이터의 정렬 여부에 따라 선택하기
데이터의 정렬 여부에 따라 ArrayList나 LinkedList, TreeSet을 선택할 수 있습니다. 데이터가 정렬되어 있지 않은 경우에는 ArrayList나 LinkedList를 사용하는 것이 좋습니다. TreeSet은 데이터를 정렬하여 저장하기 때문에 정렬된 데이터를 사용할 때 효과적입니다.
4. 동기화 여부에 따라 선택하기
멀티스레드 환경에서는 동기화된 컬렉션 클래스를 사용해야 합니다. 동기화된 컬렉션 클래스로는 Vector, Hashtable, synchronizedList, synchronizedSet, ConcurrentHashMap 등이 있습니다. 멀티스레드 환경에서는 동시성 문제가 발생할 수 있으므로, 이를 고려하여 적절한 컬렉션 클래스를 선택해야 합니다.
5. 데이터의 검색 빈도에 따라 선택하기
데이터의 검색 빈도에 따라 HashMap, TreeMap, LinkedHashMap 중 하나를 선택할 수 있습니다. 검색 속도가 빠른 HashMap은 데이터의 순서가 중요하지 않은 경우에 유용합니다. 순서가 중요한 경우에는 TreeMap이나 LinkedHashMap를 사용하는 것이 좋습니다.
6. 쓰레드 안전 여부에 따라 선택하기
쓰레드 안전 여부에 따라 ConcurrentHashMap, CopyOnWriteArrayList, CopyOnWriteArraySet 등의 컬렉션 클래스를 선택할 수 있습니다. 이들은 멀티스레드 환경에서 안전하게 사용할 수 있습니다.
7. 메모리 사용량과 성능에 따라 선택하기
메모리 사용량과 성능에 따라 ArrayList나 LinkedList, HashSet나 TreeSet, HashMap나 TreeMap 중 하나를 선택할 수 있습니다. 메모리 사용량이 적은 ArrayList나 HashSet을 사용하면 속도가 빨라질 수 있습니다. 대용량 데이터를 다룰 때는 LinkedList나 TreeSet, TreeMap을 사용하는 것이 좋습니다.
8. 컬렉션의 특징에 따라 선택하기
컬렉션의 특징에 따라 선택하는 것도 중요합니다. 예를 들어, ArrayList는 순차적인 데이터 처리에 유용하며, HashSet은 중복 데이터 처리에 유용합니다. 이러한 특징을 고려하여 적절한 컬렉션 클래스를 선택하는 것이 좋습니다.
String은 불변객체(immutable object)입니다. 즉, 한번 생성된 String 객체는 내부의 값이 변경될 수 없습니다. 이는 String 객체의 내용이 변경되지 않도록 보장하기 위해서입니다. 만약 String 객체가 변경되면 다른 객체에서도 해당 값에 접근하는 것이 불안정해지기 때문입니다.
2. 접근제어자의 종류와 특징?
자바에서 접근제어자(access modifier)는 클래스, 필드, 메서드 등의 멤버에 대한 접근 권한을 제어합니다. 다음은 접근제어자의 종류와 특징입니다.
public: 어떤 클래스에서도 접근 가능합니다. protected: 같은 패키지에서는 접근 가능하고, 다른 패키지의 자식 클래스에서도 접근 가능합니다. default(package-private): 같은 패키지에서만 접근 가능합니다. private: 같은 클래스에서만 접근 가능합니다.
3. OOP의 4가지 특징?
OOP(Object-Oriented Programming)의 4가지 특징은 다음과 같습니다.
캡슐화(encapsulation): 객체의 상태와 행동을 하나의 단위로 묶고 외부에서의 접근을 제어합니다. 상속(inheritance): 상위 클래스의 속성과 메서드를 하위 클래스에서 재사용할 수 있도록 합니다. 다형성(polymorphism): 같은 타입 또는 같은 인터페이스를 구현하는 객체들이 동일한 메서드를 호출하여 다른 방식으로 동작할 수 있도록 합니다. 추상화(abstraction): 객체의 복잡한 구조와 동작을 간단한 모델로 단순화하여 표현합니다.
4. 캡슐화와 은닉화의 특징?
캡슐화와 은닉화는 객체지향 프로그래밍에서 데이터 보호와 관련된 개념입니다.
캡슐화(encapsulation): 객체의 상태와 행동을 하나의 단위로 묶고, 외부에서의 접근을 제어합니다. 캡슐화를 통해 객체의 내부 구현과 상태를 보호하고, 객체 간의 결합도를 낮춰 유지보수와 확장성을 높일 수 있습니다. 은닉화(data hiding): 객체의 내부 구현을 외부에 노출하지 않는 것입니다. 객체의 내부 데이터를 외부에서 직접 접근하지 못하도록 하여 데이터 보호함으로써 객체의 무결성을 보장하고, 객체의 내부 구현을 변경해도 외부 인터페이스를 유지할 수 있습니다. 은닉화를 통해 객체의 내부 구현을 감추고, 외부에서는 객체의 인터페이스를 통해 상호작용할 수 있습니다.
5. OOP의 5대 원칙?
OOP의 5대 원칙(SOLID)은 다음과 같습니다.
SRP(Single Responsibility Principle): 클래스는 하나의 책임만 가져야 합니다. OCP(Open-Closed Principle): 확장에는 열려있고, 변경에는 닫혀있어야 합니다. LSP(Liskov Substitution Principle): 하위 클래스는 상위 클래스를 대체할 수 있어야 합니다. ISP(Interface Segregation Principle): 인터페이스는 클라이언트에 필요한 메서드만 제공해야 합니다. DIP(Dependency Inversion Principle): 추상화에 의존해야 하며, 구체화에 의존하지 않아야 합니다.
6. JVM 구조?
JVM(Java Virtual Machine)은 자바 프로그램을 실행하는 가상 머신입니다. JVM은 3가지 구성 요소로 이루어져 있습니다.
Class Loader: 컴파일된 자바 클래스 파일을 메모리에 로딩합니다. Execution Engine: 로딩된 클래스 파일을 실행합니다. Runtime Data Areas: JVM에서 메모리를 관리하는 영역으로, Method Area, Heap, Java Stack, Native Stack 등으로 구성됩니다.
7. 클래스, 객체, 인스턴스의 차이?
클래스는 객체를 만들기 위한 일종의 설계도이며, 객체는 클래스를 통해 생성된 실체입니다. 인스턴스는 객체가 메모리에 할당된 상태를 의미합니다.
8. interface와 abstract class의 차이?
interface와 abstract class는 모두 추상화를 위한 개념입니다. 다음은 둘의 차이점입니다.
interface는 모든 메서드가 추상 메서드이며, 구현부를 가질 수 없습니다. 반면, abstract class는 추상 메서드와 구현된 메서드를 모두 포함할 수 있습니다. interface는 다중 상속이 가능합니다. 반면, abstract class는 단일 상속만 가능합니다. interface는 클래스에서 implements 키워드를 사용하여 구현합니다. 반면, abstract class는 extends 키워드를 사용하여 상속합니다.
9. CheckedException과 UncheckedException의 차이?
CheckedException은 예외 처리가 강제되는 예외입니다. 컴파일 시점에서 예외 처리를 확인하며, 예외를 처리하지 않으면 코드를 컴파일할 수 없습니다. 대표적인 예로는 IOException, ClassNotFoundException 등이 있습니다. 반면, UncheckedException은 예외 처리가 강제되지 않는 예외입니다. 컴파일 시점에서 확인하지 않으며, 런타임 시점에서 예외가 발생합니다. 대표적인 예로는 NullPointerException, ArrayIndexOutOfBoundsException 등이 있습니다.
10. Call by Reference와 Call by Value의 차이?
Call by Value는 메서드 호출 시 인자로 전달된 값의 복사본을 생성하여 사용합니다. 메서드 내부에서 복사본을 변경해도 원본 값에는 영향을 주지 않습니다. 반면, Call by Reference는 메서드 호출 시 인자로 전달된 값의 메모리 주소를 참조합니다. 따라서 메서드 내부에서 값이 변경되면 원본 값에도 영향을 주게 됩니다.
11. 오버로딩과 오버라이딩의 차이?
오버로딩(Overloading)은 같은 이름의 메서드를 여러 개 정의하는 것을 말합니다. 매개변수의 개수, 타입, 순서가 다르면 오버로딩이 가능합니다. 반면, 오버라이딩(Overriding)은 상위 클래스에서 정의된 메서드를 하위 클래스에서 재정의하는 것을 말합니다. 메서드의 시그니처(이름, 매개변수 타입, 반환 타입)가 동일해야 합니다.
12. 스레드세이프(Thread-Safe)
스레드세이프란 여러 스레드가 동시에 접근해도 안전하게 사용할 수 있는 코드를 말합니다. 스레드세이프한 코드는 멀티스레드 환경에서 동시성 문제를 방지하고, 데이터의 일관성을 유지합니다.
13. Garbage Collector는 어떻게 동작하는지?
Garbage Collector는 JVM에서 사용되지 않는 객체를 자동으로 해제하는 기능입니다. Garbage Collector는 객체가 생성된 시점, 참조되지 않는 시점 등을 추적하여 사용되지 않는 객체를 메모리에서 해제합니다.
14. 제네릭을 왜 쓰는지?
제네릭은 자바에서 컬렉션의 타입 안정성을 보장하기 위해 사용됩니다. 제네릭을 사용하면 컬렉션에 저장된 요소의 타입을 컴파일 시점에 확인할 수 있으며, 타입안정성이 높아집니다. 또한 제네릭은 코드의 재사용성을 높여줍니다. 제네릭을 사용하면 같은 코드를 여러 타입에서 사용할 수 있기 때문입니다.